- TOP
- >
- ディープ・テック事業
- >
- 人工知能研究所
- >
- 研究および開発方針
研究および開発方針
- 「PROJECTα」では、3つのプロジェクトチームが立ち上がり、有機的に連携しながら並走しています。1つ目は、「数理解析班」と呼ばれており、当社の金融事業の投資リターンの源泉たる強みとしての特徴量を数学的に抽出することを目的としています。2つ目は、「機械学習班」です。メカニズムの解明はさておき、社内外のデータを学習させることで、当社の哲学や方法論に沿った新しい投資アイデアを生むこと、あるいは投資アイデアを生むために有用な情報を絞り込むことを目的としています。3つ目は、「データベース班」です。当社固有のプライベート・データの収集に始まり、その後の研究や開発を見据えたデータ環境の整備を目的としています。
-
-
- 1.数理解析班の取組の一例
-
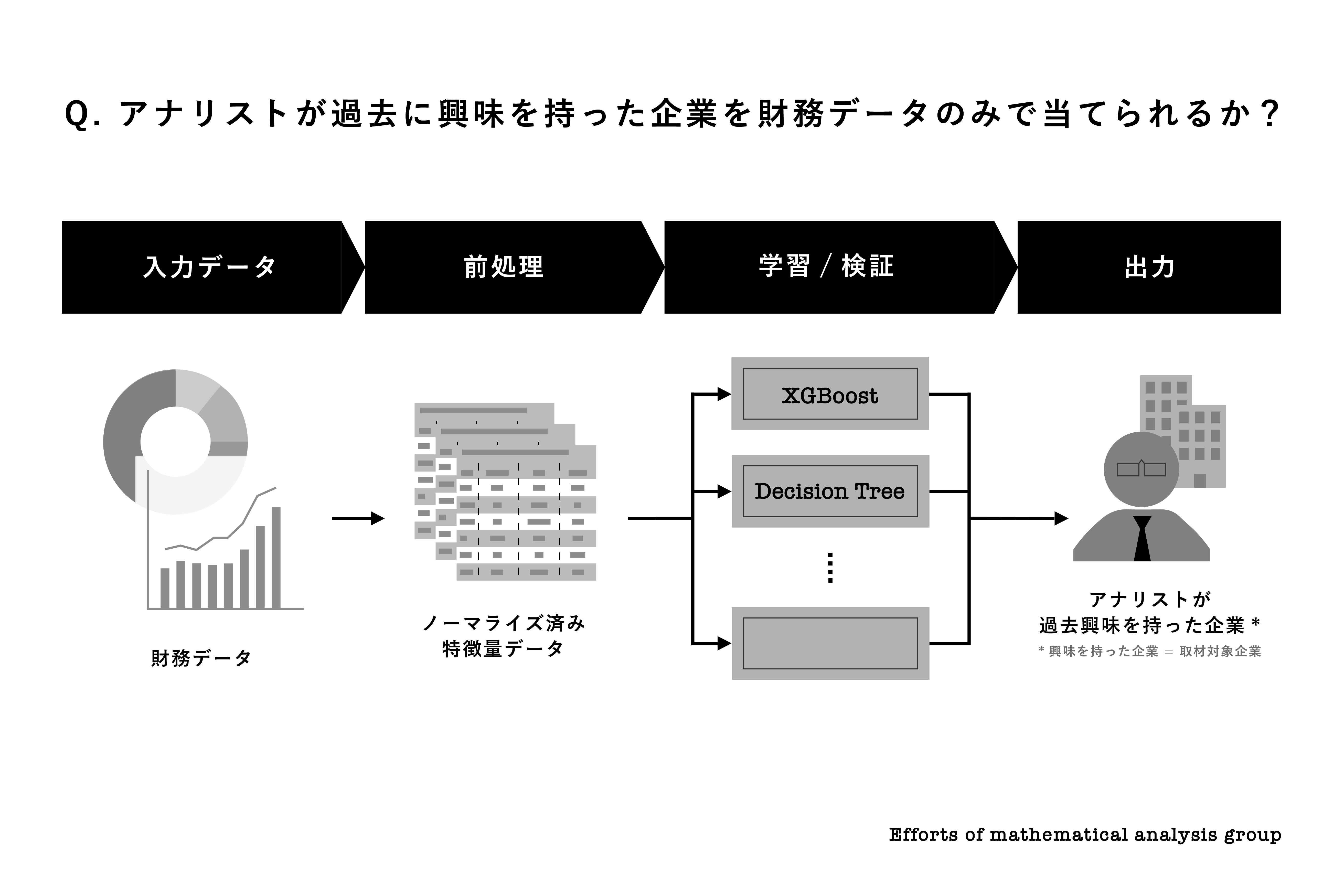
当社の企業アナリストは様々な定量、定性データに触れながら、それを頭の中で取捨選択あるいは統合して最終的な投資アイデアの立案に至ります。定量データでいえば、売上、費用、利益などの企業財務データに始まり、PERやPBRなどの投資分析指標、そして過去の株価データも含まれます。
数理解析班は、これら膨大な定量データの中で、まずは「PERやPBRなどの投資分析指標」に注目しました。「当社のアナリストが興味を持ったかどうか」を目的変数として、どのような投資分析指標が説明変数としての能力が高いのかを、GLM、SVM、XGBoostなどのアルゴリズムを用いて、直線的あるいは非直線的な解析の両方に挑戦しています。また、局面によって十分なnが確保できない場合にはLASSOなどスパースモデリングの手法を用いることもあります。ここから説明変数としての候補の広がりはもちろん、その膨大な組合せという壁、目的変数はそもそも「調査を行ったか」でよいのかという思索などの冒険が待ち構えています。数理解析班は説明変数・目的変数の設定に始まり、手法の選定など自由度高く活動しています。
-
- 2.機械学習班の取組の一例
-
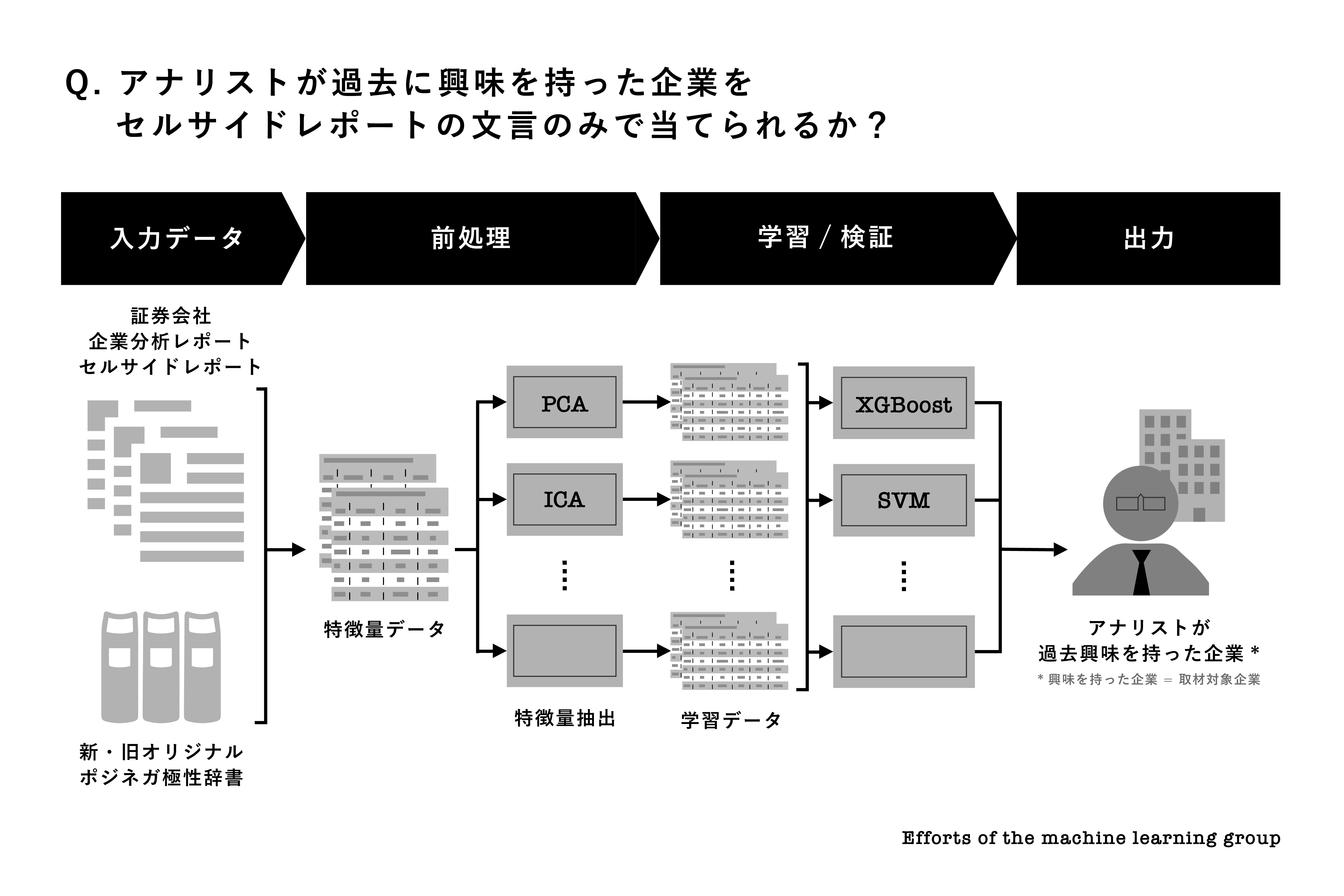
上述の定量データに加えて、定性データもまた膨大に存在しています。その代表は、当社が10年以上にわたり継続している、投資先候補企業の経営陣の皆様との議論の中身、インタビュー結果です。更には新聞記事もそうですし、証券会社の企業分析アナリストが発行する企業調査レポート(いわゆるセルサイド・レポート)もそれに該当します。これらの中に、投資判断に有用な情報、あるいはその組み合わせの妙が隠されているはずです。
機械学習班は、これら膨大な定量データの中で、まずはセルサイド・レポートに着目しました。固有の辞書を作成し、「当社のアナリストが本セルサイド・レポートを読んだ後に興味を持ったか」を目的変数として、これをディープラーニングにかけることで、当社の哲学や方法論に沿ったレポートを抽出しうるのかに挑戦しています。データ数に応じてXGBoostや半教師あり学習など他の機械学習アルゴリズムを使っています。今後はBERTなどの最新の自然言語処理アルゴリズムを組み込んだ予測モデルを開発していく予定です。機械学習班も、目的変数や説明変数の選定から、採用する学習方法まで、同じく自由度高く活動しています。
-
- 3.データベース班の取組の一例
-
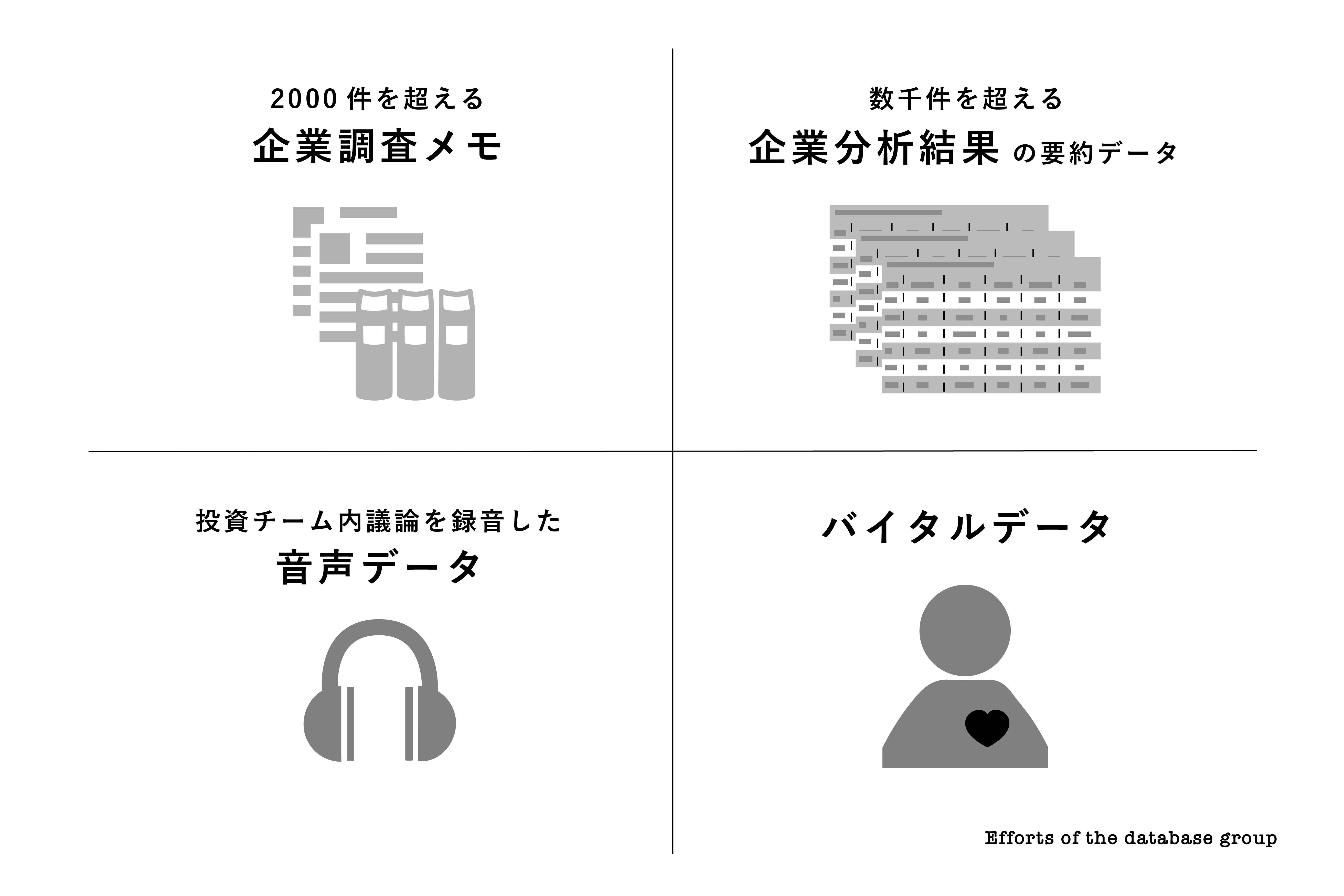
数理解析班と機械学習班があらゆる試行ができるように定量、定性データを利用しやすいかたちで整備する計画です。先述のとおり、定量パブリック・データで言えば企業の財務データ、投資分析指標、過去の株価データなどが存在しています。これらを利用可能なかたちで整備を進めています。
一方でデータのクレンジングをしているだけではなく、先進的な取り組みも想定しています。例えば、当社固有の定量プライベート・データの取得にも着手する必要がありますが、投資チームにおける口頭での議論を効率よくデータ化したり、その時のバイタル・データもあわせて取得するにはソリューションの開発あるいは導入が必要です。
更には、そのデータベースに上記2班の挑戦から得られた知見を埋め込んで、「ヒトの投資意思決定を導くデータベース」というプロダクトの開発も見据えています。
-
© HAYATE GROUP
